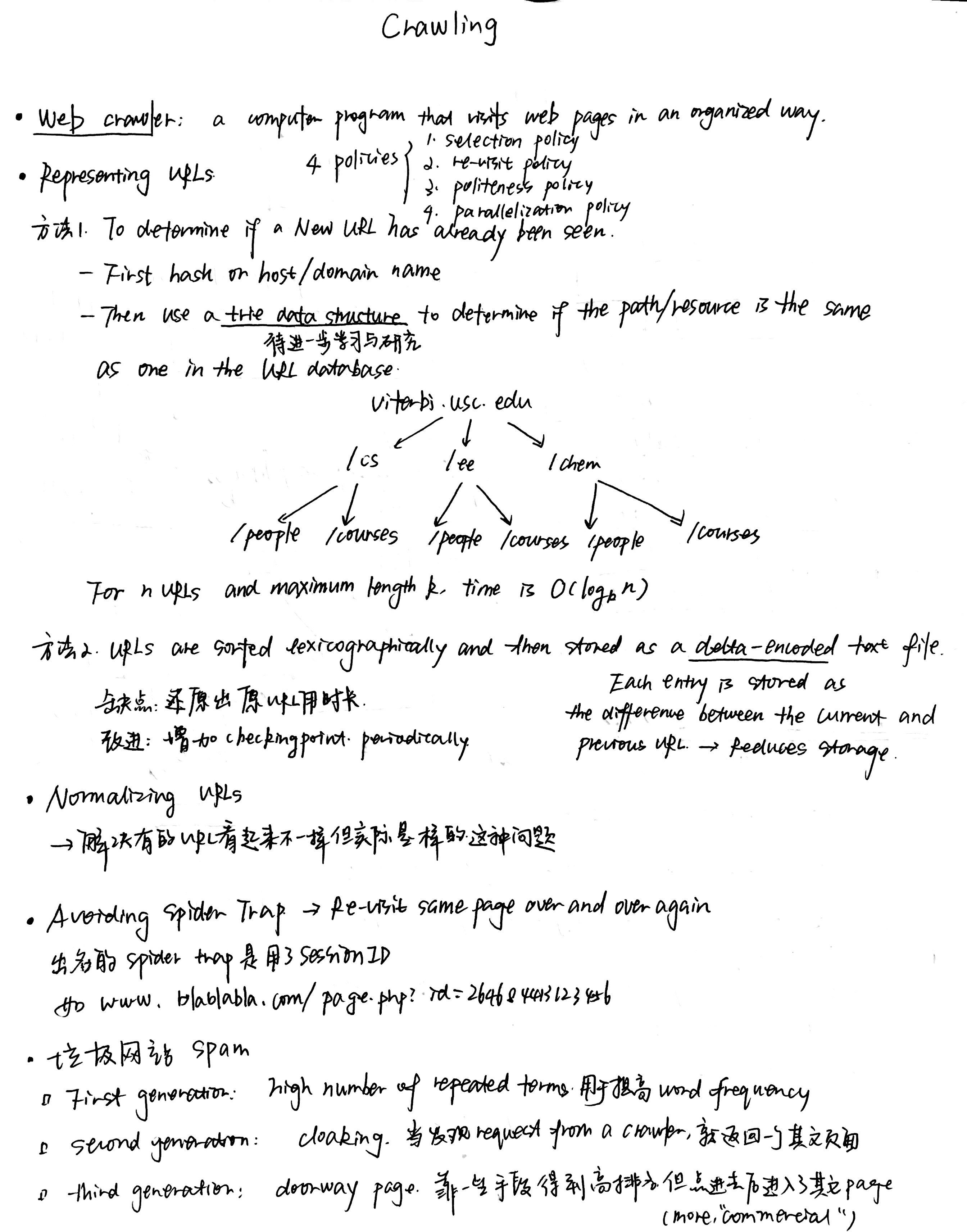
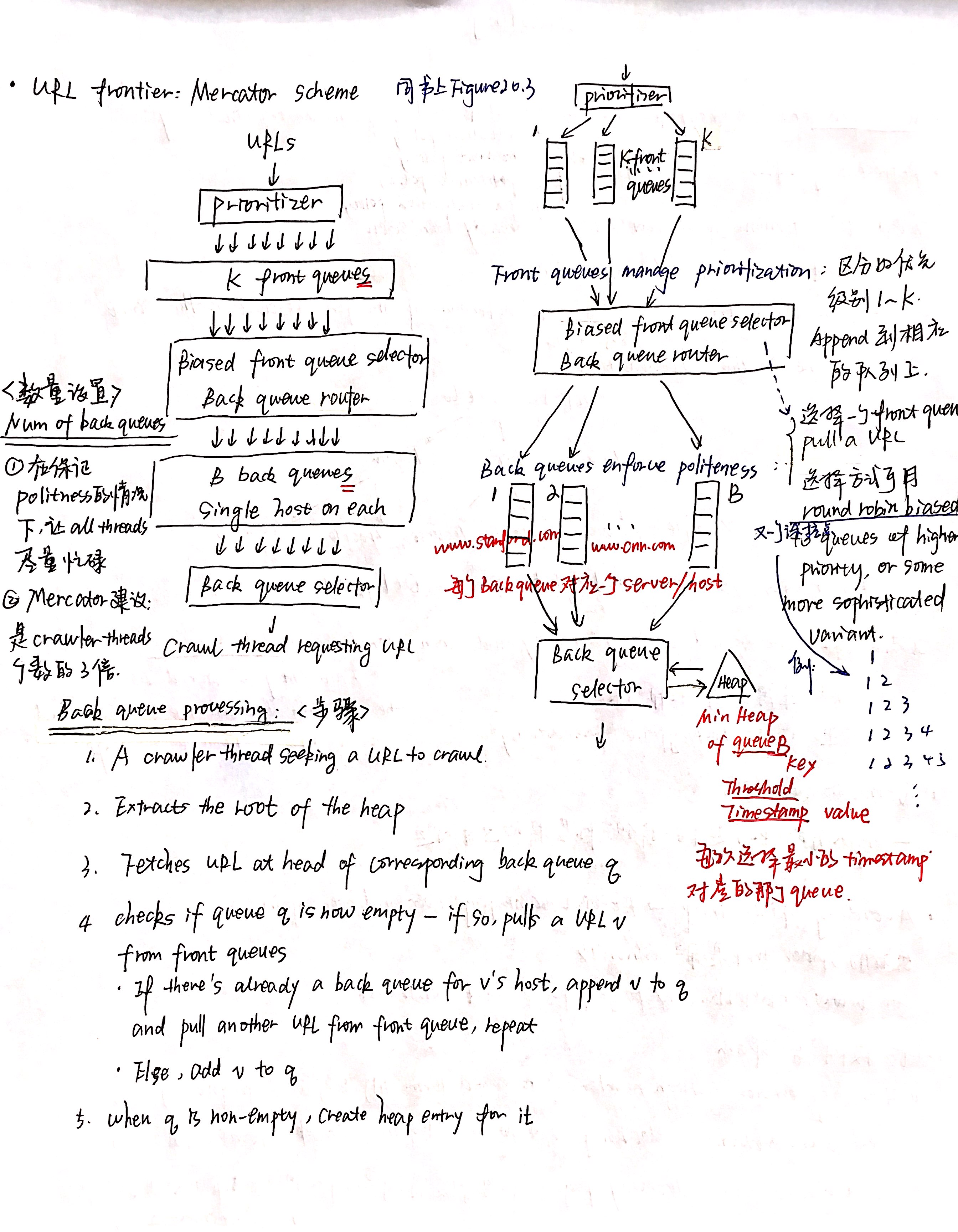
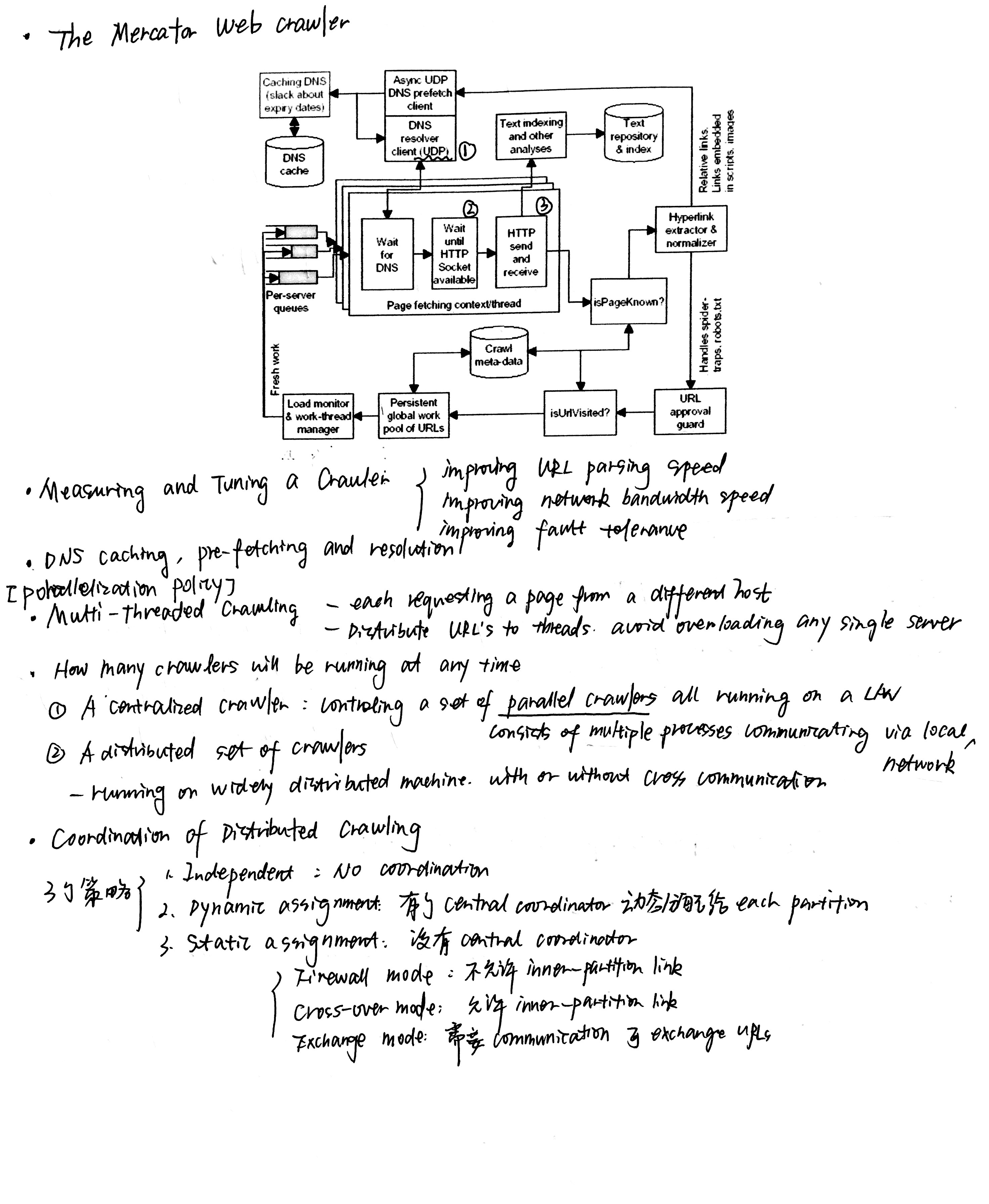
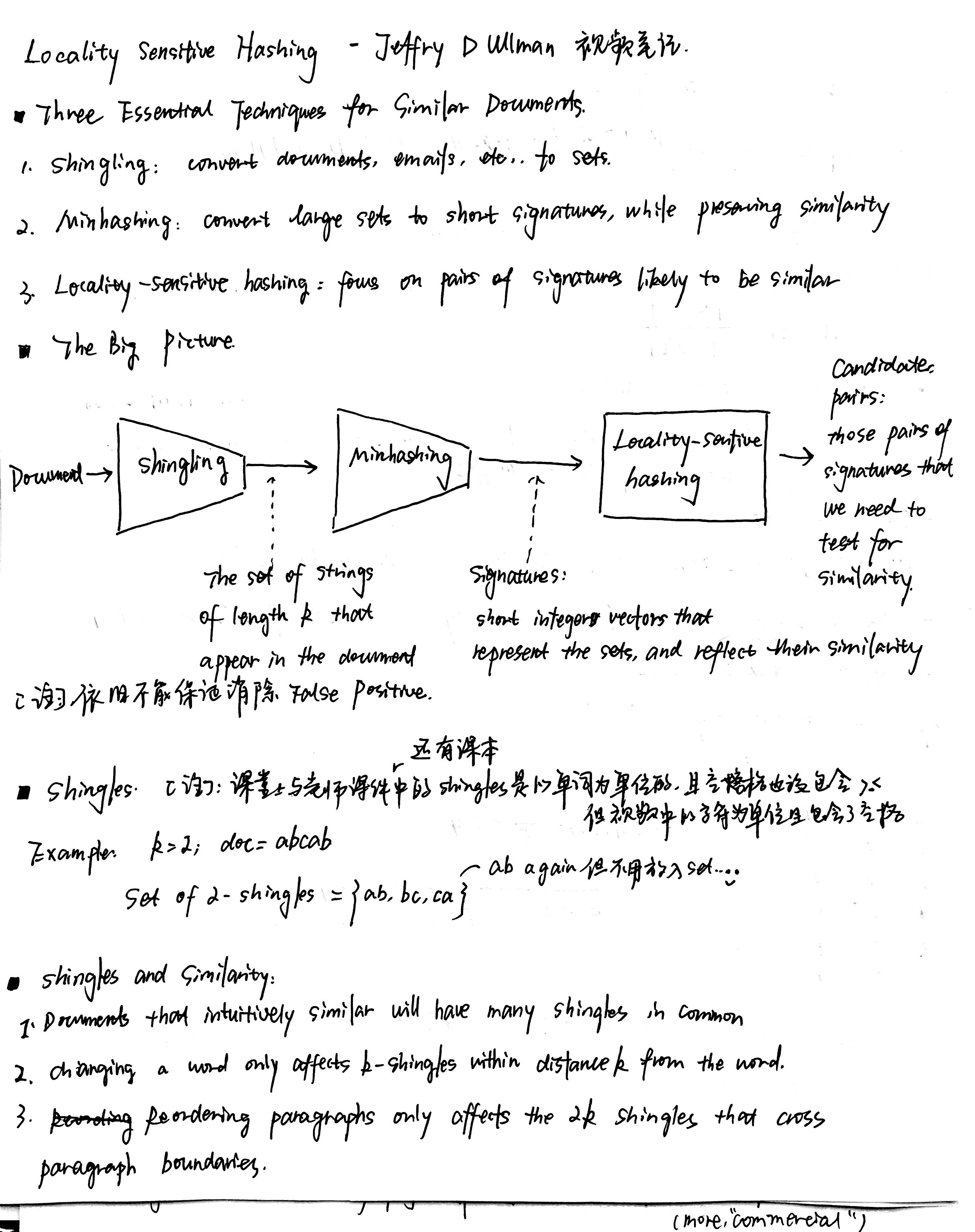
我自己本身也很喜欢男装的简洁和大方,逛起来都差不多,不像女孩子的衣服看起来眼花缭乱…
鉴于身边男性程序员朋友很多,决定写一个男装搭配的小博文。
我希望文章可以让大部分普通的男孩子收益,大长腿大高个身材好的就自己随便搭配吧,感觉都不会丑到哪里去…..
— 题记
准则
- 衣服不要皱不要皱不要皱,不要穿皱皱的外套,皱皱的t恤。
关于衣服皱这个,洗完衣服好好展开。然后买衣服的时候注意一下质量! - 头发不要油. 不用打摩丝什么的,就清清爽爽就好。
- 脸也不要太油光泛滥了,用些洗面奶就可以,基本的护肤还是需要的我觉得。
- 背不要弯。
- 有的男孩子肩膀窄,我不喜欢肩膀窄的男孩穿软塌塌的那种外套。。就显得更窄了没有男友力囧。
- 建议衣服自己按照一套套的搭配好,或者按照对应的关系搭配。比如自己会清楚的知道买这个裤子有哪些上衣配。这样很节约时间。
品牌推荐
一年四季篇
https://www.zhihu.com/question/58162135
亮色
我发现好多男孩子都喜欢亮色 - 橙色,黄色,蓝色为主!而且都是那种颜色十分纯的!记得以前美术老师和我们说,一般小孩子都很喜欢这种纯度很高的颜色,长大了会喜欢有点灰度的。哈哈哈,如果你喜欢纯色!说明你有个大大的童心:)
知乎里很多帖子都是黑白灰走气质路线。不过我们也不能为了帅气就抛弃自己挚爱的骚气! 我自己觉得纯色是一种很可爱的颜色!尤其是那种平时很正经突然来一个亮色,有一种十分活泼的感觉!
一般我没见到太多人穿纯彩色的裤子,一般都是外套和t恤占多数。还有骚气外露的各种鞋子。