定义
De-duplication – the process of identifying and avoiding essentially identical web pages
With respect to web crawling, de-duplication essentially refers to the identification of identical and nearly identical web pages and indexing only a single version to return as a search result
对于相同或者相近的网页,只留下一个版本
[例子]
- the URL’s host name can be distinct (virtual hosts),
- the URL’s protocol can be distinct (http, https),
- the URL’s path and/or page name can be distinct
不同的地址指向相同的网站
http://maps.google.com
https://www.google.com/maps
相类似的网站
比如一个网页前后相隔几秒的版本
镜像
Mirroring is the systematic replication of web pages across hosts.
是造成duplicate的一个重要原因
Host1/α and Host2/β are mirrors iff:
例如 https://www.apache.org/dyn/closer.cgi
[解释]
- 在云计算中也经常提到De-duplication的概念,但是与此处所说的并不一样
解决Duplication/Near-Duplication的问题
Duplication
[方法] compute fingerprints using cryptographic hashing, 如 SHA-1 和 MD5。有序排列,方便查找logN
Near-Duplication
[方法] compute the syntactic similarity, and use a similarity threshold to detect near-duplicates
这里具体介绍两种方法
- 通过计算w-Shingles和Jaccard Similarity来得到相似度
[参考视频] https://www.youtube.com/watch?v=bQAYY8INBxg
[视频笔记]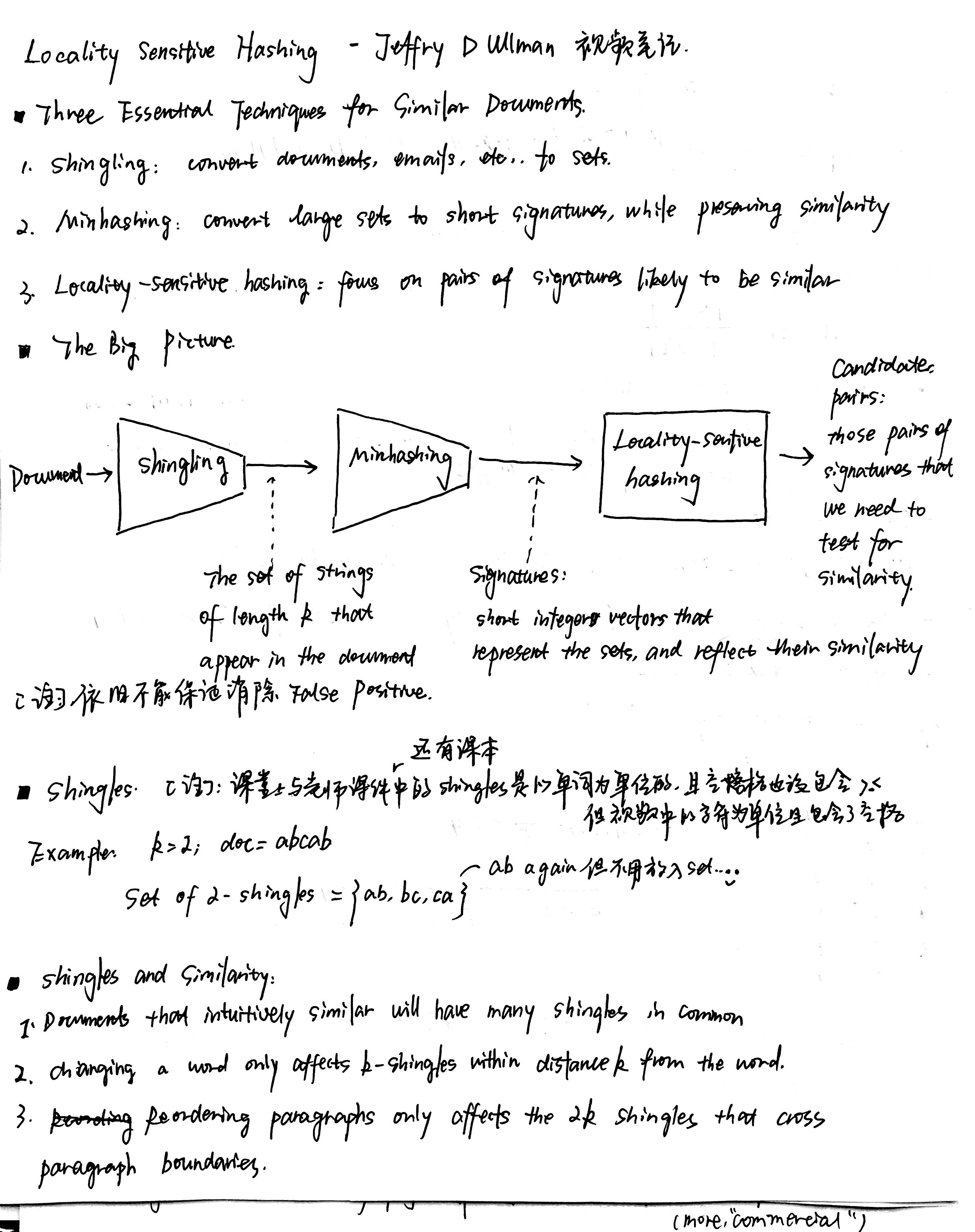



- 通过fingerprints来计算similarity
[SimHash] Simhash is one where similar items are hashed to similar hash values
(by similar we mean the bitwise Hamming distance between hash values)1234567891011pick a hashsize, lets say 32 bitslet V = [0] * 32 # (ie a vector of 32 zeros)break the input phrase up into shingles. e.g.'the cat sat on the mat'.shingles(2)=>#<Set: {"th", "he", "e ", " c", "ca", "at", "t ", " s", "sa", " o", "on", "n ", " t", " m", "ma"}>hash each feature using a normal 32-bit hash algorithm. e.g."th".hash = -502157718 "he".hash = -369049682 ...for each hashif bit_i of hash is set then add 1 to V[i]if bit_i of hash is not set then take 1 from V[i]simhash bit_i is 1 if V[i] > 0 and 0 otherwise
[通过SimHash找到相似的页面]
- 如果两个SimHash的Hamming distance相近,则如果将所有SimHash有序排列,它们会位于比较相近的位置
- 数字位左移或者右移相同的位置,其相对Hamming distance不改变
因此可以这样做123rotate the bits B times (B is the length of vector)sortcheck adjancent