Definition of an Inverted index
An inverted index is typically composed of a vector containing all distinct words of the text collection in lexicographical order (which is called the vocabulary) and for each word in the vocabulary, a list of all documents (and text positions) in which that word occurs
通俗的说: 单词到包括该单词的文档的集合的映射。
注释: 这里的单词可能是被处理过的,一些常用的处理方法有
- Case folding: converting all uppercase letters to lower case
- Stemming: reducing words to their morphological root
- Stop words: removing words that are so common they provide no information
Inverted index 的应用情景
假设有这样一个Query:
|
|
方法一 暴力搜索
先找到所有包含Brutus和Caesar的话剧,再逐字排查,如果含有Caplurnia就删除掉该话剧。
缺点:
- Too slow
- 需要很大的空间
- 不够灵活,不支持其他的操作,比如”Find the word Romans near countrymen”
方法二: Term-Document Incidence Matrix
用了 Bit Map 位运算的思想。构建如下矩阵,(t,d)=1代表term t在document d中出现,0代表没有出现。例如:
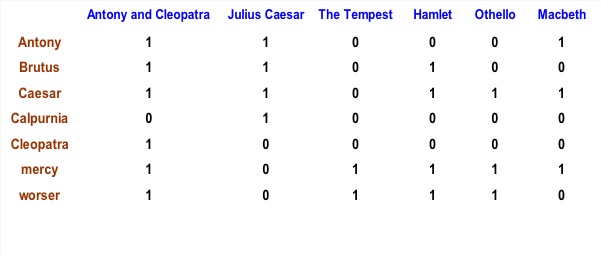
这样对于上一个查询,只需要
110100 AND 110111 AND 10111 = 100100
所以the two plays matching the query are:
“Anthony and Cleopatra”, “Hamlet”
缺点:
- 需要很大的空间,并且矩阵通常十分稀疏:
|
|
方法三: Inverted Index
在数据结构上我们选择了链表而不是数组,链表的优势在于:
- Dynamic space allocation
- Insertion of terms into documents easy
- There is space overhead of pointers, though this is not too serious
Inverted Index的构建如下图所示

应用举例:
|
|
Skip Pointers
目的: speed up the merging of postings
方法解释:如图所示
算法
|
|
适用范围:
- Index 相对固定 update的次数比较少: Building effective skip pointers is easy if an index is relatively static; it is harder if a postings list keeps changing because of updates. A malicious deletion strategy can render skip lists ineffective.
- the presence of skip pointers only helps for AND queries, not for OR queries.
问题: How many skip pointers should we add?
- TradeOff Problem:
- More skips -> shorter skip span => more likely to skip. But lots of comparision to skip pointers
- Fewer skips -> few pointer comparision, but then long skip spans => few successful skips
- Simple Heuristic
- 用Length的平方根: for a postings list of length P, use sqrt{P} evenly-spaced skip pointers.
硬件对速度的影响
Choosing the optimal encoding for an inverted index is an ever-changing game for the system builder, because it is strongly dependent on underlying computer technologies and their relative speeds and sizes. Traditionally, CPUs were slow, and so highly compressed techniques were not optimal. Now CPUs are fast and disk is slow, so reducing disk postings list size dominates. However, if you’re running a search engine with everything in memory then the equation changes again.
Phrase Queries
之前所说的inverted index技术是基于Term的,但是在实际运用中我们经常会查询一个短语,而不是单词,比如:stanford university
这里阐述两个方法
方法一: Bi-word indexes (2-grams, 2 shingles)
方法介绍
- A bi-word (or a 2-gram) is a consecutive pair of terms in some text。比如 “Friends, Romans, Countrymen” 会生成 “friends romans” 和 “romans countrymen”
- Each of these bi-words is now added to the dictionary as a term。也就是说之前的Term变成了现在的bi-words。
缺点
- 数量爆炸!Bi-words will cause an explosion in the vocabulary database
- 短语长度也许大于2。Queries longer than 2 words will have to be broken into bi-word segments
方法二: Positional indexes
方法介绍
相比于之前的inverted index, 这里其实就是多记录了一个Term出现的位置位置:

比方说我们要查询
|
|
现在我们首先找to be, 步骤如下
|
|
算法
|
|